Rolling out a CMS mid-pandemic
View human-generated summary 🧬
- maybe don't launch your product in the height of a pandemic
- if you do, be prepared and be kind to yourselves
- anyway it doesn't matter we're never going to have another pandemic, right?
It was February 2020. Spark, our in-house Content Management System, was preparing for a major milestone — launching to all the news desks.
Everything was going to plan. Our team had a session to run through the risks and roll out plan. Training sessions were booked with the new users. We had seats beside the main news desk so we could be on hand to support and gather feedback. Celebratory cupcakes and stickers were being ordered.
Then, the world changed.
What is Spark?
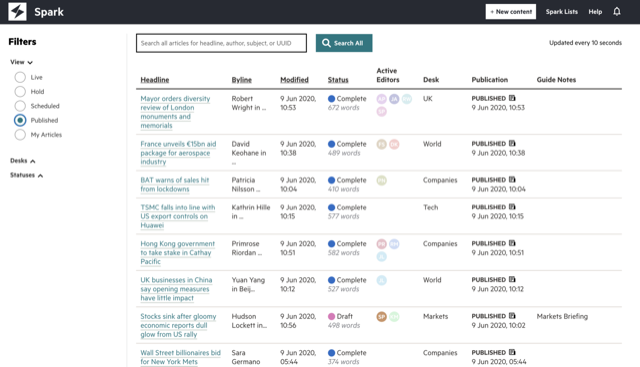
Spark is a new content management system for FT journalists. It is an easy-to-use tool for journalists to write, edit, produce and publish stories on any device, anywhere in the world. Spark integrates with our other newsroom tools and allows reporters and editors to collaborate on stories within the publishing system, for the first time.
This is a major engineering project representing about two years of close co-operation with the FT newsroom. It started off as a scrappy prototype to be used by our FT Alphaville reporters, and over the past 18 months built up to a full-featured, browser-based modern CMS that will allow us to innovate on new ways of storytelling.
By March, about 100 journalists from a handful of news desks had already joined Spark and were using it daily to publish their stories. This next phase would introduce around 300 new users around the world, including all our main news desks. Spark would now be responsible for publishing breaking news stories and updating the FT.com homepage, 24/7 — a big deal!
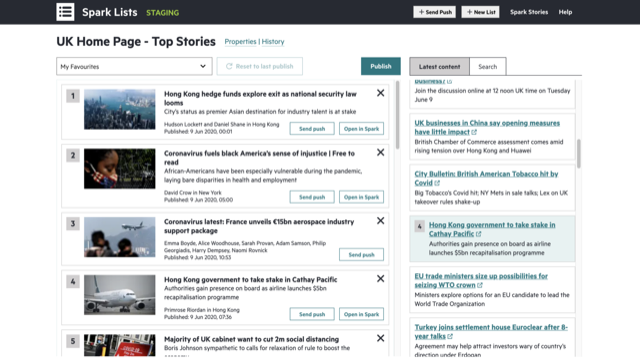
And then came Lockdown...
It seemed as though the launch would be postponed. There was some nervousness around introducing a new system during an already chaotic time, with journalists working around the clock to cover the coronavirus crisis. Both our development team and editorial were adjusting to working fully remotely for the first time. Some of our users hadn’t yet been trained. Rolling out Spark now seemed more daunting than ever.
But on the flip side, there were some compelling reasons to go ahead with it. Many of the benefits that Spark provides were amplified by the situation:
- Spark was built as a tool to be used anywhere, at any time, from any device — this was more relevant now than ever.
- Features such as collaboration and commenting would aid the communication between reporters and editors — as vouched for by some of our existing users.
- Being cloud-hosted and behind single sign on meant that we could ease some of the demand on our VPN.
Beyond that, we had no idea when normality would resume. If we didn’t roll it out now, then when would we? So we did it.
How did it go?!
All things considered, the roll out was a success! It was by no means smooth sailing. Despite our earnest efforts with load testing, our first day was riddled with latency and reliability issues, which we resolved with a host of infrastructure upgrades and prompt architecture changes. Within days we found that all the strange edge cases that seemed inconceivable would start happening to pockets of users.
Launching a product of this scale and importance was always going to be tough. As a team we’ve had our fair share of practice dealing with incidents and thinking on our feet. However, doing this in the situation we were in provided a whole new set of challenges. Here are some of the things we learnt as a result.
What we learnt?
Have a dedicated co-ordinator
During an incident in an office, it’s usually pretty easy to see who’s doing what just by walking over to their desk. Even for normal out of hours incidents, there’s usually only one or two engineers involved in fixing.
When rolling out Spark, we had 9 engineers all working remotely across a handful of different issues. This often got quite chaotic and hard to track. We assigned a single person as a “co-ordinator” — responsible for responding to issues raised and ensuring that critical issues were worked on. This allowed the rest of the team to focus on fixing things, and meant our stakeholders remained well informed on the status of things.
Put extra effort into communication
In spite of the above, communication within the engineering team still needed some extra attention.
Being remote made it harder to share knowledge with each other, and to know when someone needed support. As the weekend approached, it became more critical that we were all roughly aware of what issues might crop up and how to resolve them.
At the FT, we’ve recently defined an incident process, taking inspiration from Monzo, to facilitate how we resolve, communicate and learn from incidents. Admittedly it took as a few hours to follow this process in the heat of the moment, but once we did the benefits were clear. Our stakeholders had a single place to see the status of major issues, and communication amongst ourselves was more focused.
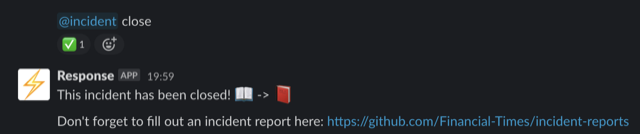
We also started making more explicit use of video calls and screen sharing. Not only did this help share knowledge amongst engineers, the “mob debugging” also led to more methodical approaches to solving problems than multiple isolated people would have been able to.
Observe all the things
Back in the office, we had the luxury of being sat right in the middle of the newsroom in our office. If anything were to go wrong, or anyone had questions — they would pop over to our desks, or we could go and check out their laptop and debug.
That luxury was no longer available to us — but thankfully we had already invested quite a bit of effort into monitoring and observability.
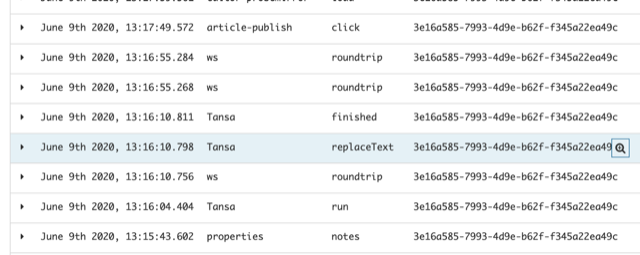
Our server logs get sent to Splunk, we use Grafana for visualising metrics, and all user actions gets stored in ElasticSearch so we can visualise it in Kibana. With this, we can answer questions such as “When was the spellchecker run on this article?” or “How many different people were collaborating on this article at once?”
Dedicated time to recover
Supporting a big launch like this was always going to be a monumental task, but it’s even more so when done virtually. Time gets blurred when you don’t see people go in and out of the office. Being on video calls all day can be immensely draining.
On the first day a lot of the team skipped lunch without any of us realising — that’s not good!
For the second day and over the weekend, our co-ordinator suggested a rota to ensure everybody got some time away from Slack. Even though nothing required us over the weekend, just knowing that you won’t be the first port of call for day was a great way to get a mental break.
(On a personal note — retaining my week off when I was due to be in sunny Portugal and instead curling up on a sofa playing Pokémon Crystal on a Game Boy Colour was an absolute joy)
Keep things in perspective
One thing we didn’t take for granted is that this was not a normal situation for anyone. Our users were busy covering perhaps one of the most important stories of our generation. As a team we had to consider our own individual circumstances — be that illness, disrupted sleep patterns, volunteering with the NHS, childcare, or just general anxiety about the state of the world. This meant being flexible with our ambitions, expectations and working patterns.
In the three months since we rolled out, we’ve published 5000 articles from Spark, and made 4000 updates to our homepage. As working from home has started to become the norm, we now have a platform that helps our editorial staff do their job efficiently. And with the rollout behind us, we can help shape new ways of telling our stories in the best way possible.